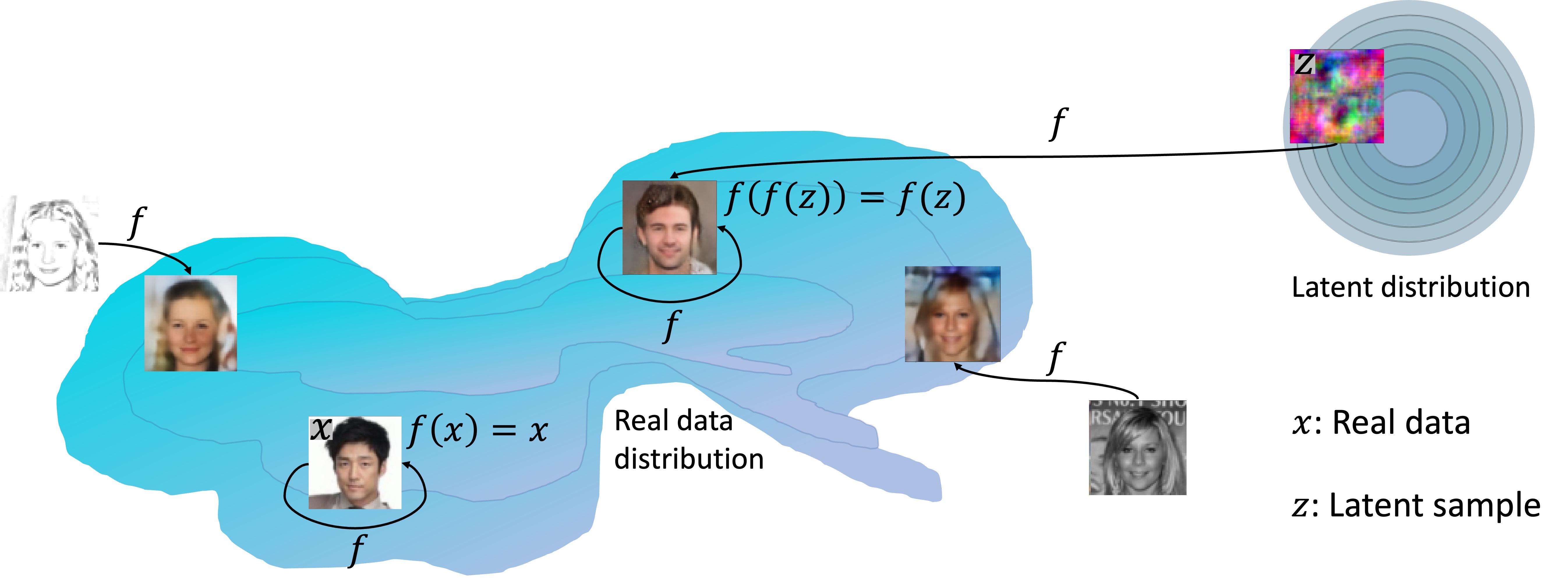
We propose a new approach for generative modeling based on training a neural network to be idempotent. An idempotent operator is one that can be applied sequentially without changing the result beyond the initial application, namely $f(f(z))=f(z)$. The proposed model $f$ is trained to map a source distribution (e.g, Gaussian noise) to a target distribution (e.g. realistic images) using the following objectives: (1) Instances from the target distribution should map to themselves, namely $f(x)=x$. We define the target manifold as the set of all instances that $f$ maps to themselves. (2) Instances that form the source distribution should map onto the defined target manifold. This is achieved by optimizing the idempotence term, $f(f(z))=f(z)$ which encourages the range of $f(z)$ to be on the target manifold. Under ideal assumptions such a process provably converges to the target distribution. This strategy results in a model capable of generating an output in one step, maintaining a consistent latent space, while also allowing sequential applications for refinement. Additionally, we find that by processing inputs from both target and source distributions, the model adeptly projects corrupted or modified data back to the target manifold. This work is a first step towards a ``global projector'' that enables projecting any input into a target data distribution.
Sequential application
Unlike inference in diffusion models, where a sequence of small steps is taken, IGN generates reasonable results in one step. In some cases (chosen here) where it is not perfect, reaplying can be used for refinement.

Latent space interpolation
We demonstrate IGN has a consistent latent space by performing manipulations, similarly as shown for GANs. We sample several random noises, take linear interpolation between them and apply $f$.

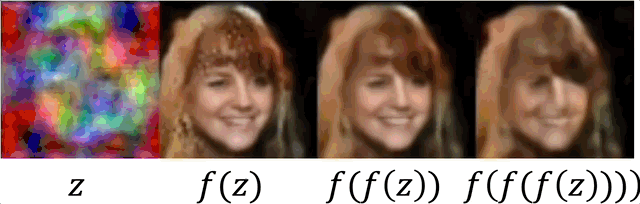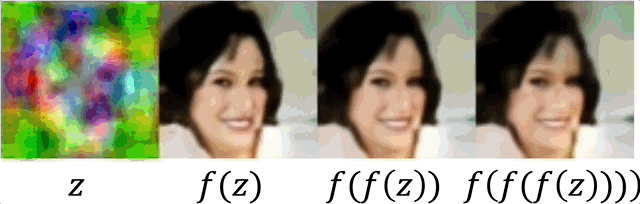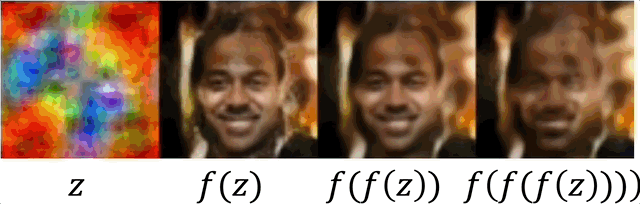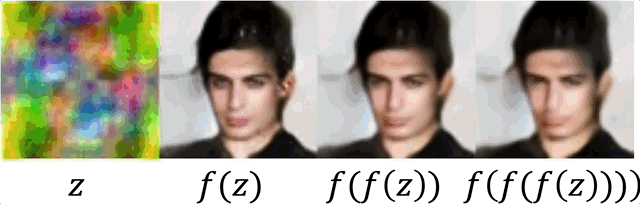
Projection onto data manifold
We validate the potential for IGN as a ``global projector'' by inputting images from a variety of distributions into the model to produce their ``natural image'' equivalents (i.e.: project onto IGN's learned manifold). We demonstrate this by denoising noised images $x+n$, colorizing grayscale images $g(x)$, and translating sketches $s(x)$ to realistic images. Note that IGN was only trained on natural images and noise, and did not see distributions such as sketches or grayscale images. This behavior naturally emerges in IGN as a product of its projection objective.

Acknowledgements
The authors would like to thank Karttikeya Mangalam, Yannis Siglidis, Konpat Preechakul, Niv Haim, Niv Granot and Ben Feinstein for the helpful discussions. Assaf Shocher gratefully acknowledges financial support for this publication by the Fulbright U.S. Postdoctoral Program, which is sponsored by the U.S. Department of State. Its contents are solely the responsibility of the author and do not necessarily represent the official views of the Fulbright Program or the Government of the United States. Amil Dravid is funded by the US Department of Energy Computational Science Graduate Fellowship. Yossi Gandelsman is funded by the Berkeley Fellowship and the Google Fellowship. Additional funding came from DARPA MCS and ONR MURI.